The Unicode code path in DMDX can either be turned on with the Unicode check box in the main DMDX dialog or a command line switch. Use of the -unicode command line switch overrides the Unicode check box. With the Unicode code path enabled DMDX uses any Unicode \u control words in the RTF file that may be present instead of the ANSI equivalents and marks up all regular ANSI characters in quotes by putting \'00 after them so they become Unicode 16 bit characters. Also as of version 5.2.3.0 of DMDX when the Unicode option is active code page references (both single and double byte ones) are converted to Unicode as some character sets require both Unicode RTF control words and code page references (Vietnamese specifically), others are completely Unicode (Tamil for instance). In addition as of version 6.1.2.12 when the Unicode option is on DMDX can now open files with names using extended characters (both code page and Unicode) and is no longer limited to just ASCII names. This means that even if you don't need the Unicode option on for your displays to be interpreted correctly if you have extended characters in the file name of a resource the Unicode option will need to be on in order for DMDX to correctly open that file. I would note that up until version 6.2.0.0 item file names were not handled as Unicode so until that release on 06/11/21 they had to be pure ANSI even if your item file itself contained the names of file resources with extended characters in them. In versions 6.1.2.12 through version 6.1.2.18 the contents of the run dialog diagnostics list box and various error messages also gained the ability display Unicode characters as it gradually occurred to me just how many different places in the code needed updating. Prior to version 6.1.3.0 unless a safe mode was active said Unicode display in the diagnostics was suppressed and you got to see the raw RTF codes, DMDX versions 6.1.3.0 and later specifically require safe mode 2 to do the same. If you've got extended characters in your item file even if you don't need the Unicode option for them to render correctly it can still be useful to use the Unicode option because it beautifies the diagnostics and error messages and makes DMDX's spew more understandable (although there's always the chance that all the extended characters used in your item file are in the same code page and that code page happens to be the active code page and thus render correctly anyway -- which is how people in Asia have been using DMDX since ages however I'm betting there's no way someone in Japan say could prepare a Chinese item file without the Unicode option active even though people can produce and display Japanese item files in Japan and Chinese people can produce Chinese item files in China, for instance we once had someone prepare a number of image files in Israel where the local page was a the Hebrew one and that had Hebrew characters in the file names but when they brought the resources to the USA and ran their item file on a machine here where the local code page is the American one they suddenly couldn't open their files, these days all they'd have to do is turn the Unicode option on and they'd be good to go, back then they had to rename them all).
As of version 6.4.0.0 of DMDX the RTF parser was modified such that Unicode outside quotes is converted to UTF-8 and passed on to the rest of DMDX (inside quotes it's converted to UTF-16); prior to that any Unicode outside quotes was just stripped out. Originally such work was conducted to provide localized keywords (that never went anywhere and the code remained disabled) however it occurred to me that using that code meant counter and macro namespace could include UTF-8 characters. So as long as the Unicode option is on and the special characters you want have a UTF-8 representation (Windings characters for instance don't) they're usable -- not only that but emoticons are in scope as well. Note that UTF-8 representations for characters range from two to four bytes (technically it's one to four bytes but those one byte options are largely the ASCII character set) and those extra characters eat into the 40 character limit on counter and macro names so if you wanted to use only emoticons you'd only be able to have nine of them (and the two mandatory periods) in the name as each emoticon is a four byte UTF-8 sequence. A side effect of the 6.4.0.0 UTF-8 treatment is that you can define macros to be Unicode sequences outside of quotes which was never possible before (there's a note below on this). The 6.4.0.0 UTF-8 modifications also affect keywords like <2Did>, <id> and <chain> where names of files are passed and in the past needed to be quoted if Unicode characters were present, this is obviated with the 6.4.0.0 modifications. Note, you'd still want to use quotes to most of those keywords if your file name contained a space.
If you're curious about your machine's ability to display Unicode glyphs or a particular glyph I coded up a displayer for them although my guess is all Windows 10 and later machines are equally good at rendering all Unicode characters (or Unicode endpoints to be technically correct), it might even be the case for Windows 7 and 8.
Note that if you're using plain text item files instead of RTF ones you must have the Unicode option off as unless DMDX parses the item file's text segments as RTF it won't be marking them up with \'00 control words and when the rest of DMDX attempts to interpret non-marked up text segments as 16 bit Unicode words all mojibake hell breaks loose.
While the Unicode code path through DMDX was initially added to see if we could get DMDX to handle a Tamil font it's also useful with double byte character set code page Asian fonts that have MS Word smart quotes in them. Because DMDX when run with the Unicode code path on is now using the Unicode RTF keywords it can differentiate between Word's smart quotes and normal characters so the smart quote detection is permanently off when the Unicode code path is on. When using legacy operating systems such as Windows XP once the Unicode path was added the problem with the Tamil font then became that Windows GDI didn't render the vowel modifiers in the correct places until we went to the Control Panel Regional and Language options and checked both the Complex right to left font handling and East Asian boxes (neither of which are present or needed in Windows 10, exactly when they went missing is something for the historians to determine). In passing we also noticed in another instance a machine rendering a Hebrew font (so right to left text) where Unicode was off and it was rendering the Hebrew backwards (remember, this was Windows XP) until we installed the right to left language option, no other changes made to DMDX, the Unicode option or the RTF file (again, not an issue in Windows 10 and probably not for some time before that OS's release). Once these options were installed DMDX's displayed output matched Word's and while Word's output may not be not technically correct (certain glyphs were not displayed) I figure once DMDX's output matches Word's my responsibility is pretty much over.
The key indicator that you need to turn the Unicode code path on is getting question marks rendered instead of the desired characters as that's what the Tamil initially looked like. In the past Asian fonts have had ANSI double byte code page alternatives to the Unicode characters, not so the Tamil. From what I've read using a ? as an alternative to Unicode characters instead of some ANSI code page alternative would appear to be a wide spread practice so perhaps others will come across this as well. It used to be that you didn't want to use Unicode all the time as there are files that contain double byte code page font references without any Unicode alternative and when you forced old versions of DMDX to use the Unicode path it took the double code page references as Unicode references and you'd get gibberish rendered (see next paragraph, they should get converted properly with 5.2.3.2 or later). The problem arose because DMDX used to expect you to either use code page values or Unicode values and not a mix of the two. When not using Unicode there's arcane code in the GDI font rendering routines that takes F0 for instance, the code page value for a Vietnamese bar-d and realizes it should use Unicode end point 111 (U+111 if you're a member of the cognoscenti that actually grok all this stuff). Turn DMDX's Unicode renderer on with versions prior to 5.2.3.2 however where it passes 16 bit values to GDI instead of 8 bit ones that F0 gets interpreted as Unicode F0 (an Icelandic eth, not what we want). Sometimes the code page value is the same as the Unicode value, but not always. And you can't just override it by editing the raw RTF and changing \'F0 to \u273 (273 decimal is 111 hex) because next time you run Word it'll go and revert them all back to code page values, I know, I tried (WordPad operates the same way). Maybe there's some way to force Word to use Unicode but I'm not seeing it. I have reports that LibreOffice will leave characters as Unicode, you might have cut and paste through NotePad++ or EditPad to get it right though.
So push came to shove and in version 5.2.3.0 of DMDX we finally added code to convert code page references to Unicode 16 bit words, which works fine when there's a code page reference DMDX can recognize in the RTF font specification, which is neither guaranteed nor error free (our table is not complete, in fact it may not be possible to build a complete one as for instance I can't find a clear Japanese code page definition given that there are three possible different choices that I have no way of choosing between without a concrete example) so conversions are by no means guaranteed. If you come up with a font that doesn't work you're more than welcome to contact me and I'll see if I can add your code page to the table DMDX uses. This could also fail if double byte character set code page characters were used however as of 5.2.3.2 DMDX currently now looks up two bytes if they occur next to each other. It appears that editors like Word use Unicode instead of double byte code page references, WordPad, not so much. I'm guessing that with the 5.2.3.2 modifications leaving the Unicode option on all the time is getting pretty close to realistic -- of course text in the diagnostics and run dialog list box became a bit tougher to read with versions of DMDX prior to 6.1.2.13, however there I've written code to convert items to UTF-8 that DMDX can now render. Prior to 6.1.2.13 if you looked at the diagnostic output you'd see what Unicode 16 bit values the double byte character set code page values had been converted to, now however if you want to see what translations were applied you'll have to look at rtfparsed.itm that contains the original markup or turn safe mode 2 on. Some of them can be translated to two 16 bit words (and of course each 16 bit word is encoded as two 8 bit \'xx RTF control words, low byte first). Also note that in the Unicode mark up you get to see the RTF text formatting control words that are removed for the diagnostics display.
Macros will require a little extra attention when the Unicode code path is on using versions of DMDX prior to 6.4.0.0. This is because regions outside of text segments prior to 6.4.0.0 were still ANSI coded 8 bit characters just like they ever were, only inside text segments was Unicode found and it's not real Unicode but instead marked up UTF-16 RTF hex sequences, now with 6.4.0.0 it's UTF-8 outside text segments and marked up UTF-16 hex sequences inside quotes. So the text segment "~M" with the Unicode path turned on gets marked up to "~\'00M\'00" and the character "ॐ" which is U+950 would be hex coded RTF \' words "\'50\'09". The macro code is smart enough that it will detect macros used outside of quotes and leave them as ANSI sequences if using versions prior to 6.4.0.0 otherwise they'll be UTF-8 and the macro code will also detect if a macro is used within quotes and mark the macro body up with \'00 correctly (or if using 6.4.0.0 the UTF-8 will be converted to UTF-16 and it will be marked up as appropriate). The problem came if you wanted to have special Unicode characters in the macro body as the RTF parser was going to strip them out as they won't be in quotes, as of version 6.4.0.0 they're now converted to UTF-8 and should be reconstituted when used inside quotes (RTF formatting however will be lost). And you can't use the double quote as a macro delimiter if there's already another text segment as it will get flagged as a frame with multiple text segments. So this would fail:
The solution is to use the keyword version of the macro definition (that I suspect never worked till I fixed it in 4.0.0.0) where the text segment is within the keyword and won't get flagged as multiple text segments:
Or you can just cheat and use a comma frame separator, because the frame with the macro definition is blank it results in no change to the display:
And of course with DMDX 6.4.0.0 the whole quote issue is moot and as long as your macro doesn't contain formatting commands. Prior to 6.4.0.0 the following example used to fail because DMDX would have stripped the Unicode out outside quotes, now it will not:
To demonstrate the loss of formatting when using 6.4.0.0 and later the following will loose the text size information and be rendered as one size so the resulting display would be formatting and not formatting (and that size being determined by whatever the surrounding text is when it's expanded); instead you have to use one of the quote delimited earlier examples like mU"formatting":
But care is still needed as use of macro U outside any text segment will freak things out totally as there's no code that strips Unicode sequences out of a macro body when used outside quotes (if it's a real problem I'll add the code but I can't see someone wanting it and only mention it for completeness' sake). As of 6.4.0.0 said Unicode will now be UTF-8 of course, tripling the oddity of errors that get thrown.
NOTE:- When using versions of DMDX prior to 6.1.2.10 and the Unicode code path was active text in an item's double quote delimited text segments displayed in the diagnostics would be marked up Unicode with \'00 control words, as of 6.1.2.10 they are removed and as of version 6.1.2.13 the rendered diagnostics should look the same as when the Unicode path is off -- unless of course you had actual Unicode characters in there... So given the following example item file:
<fd 100> <cr> <nfb>
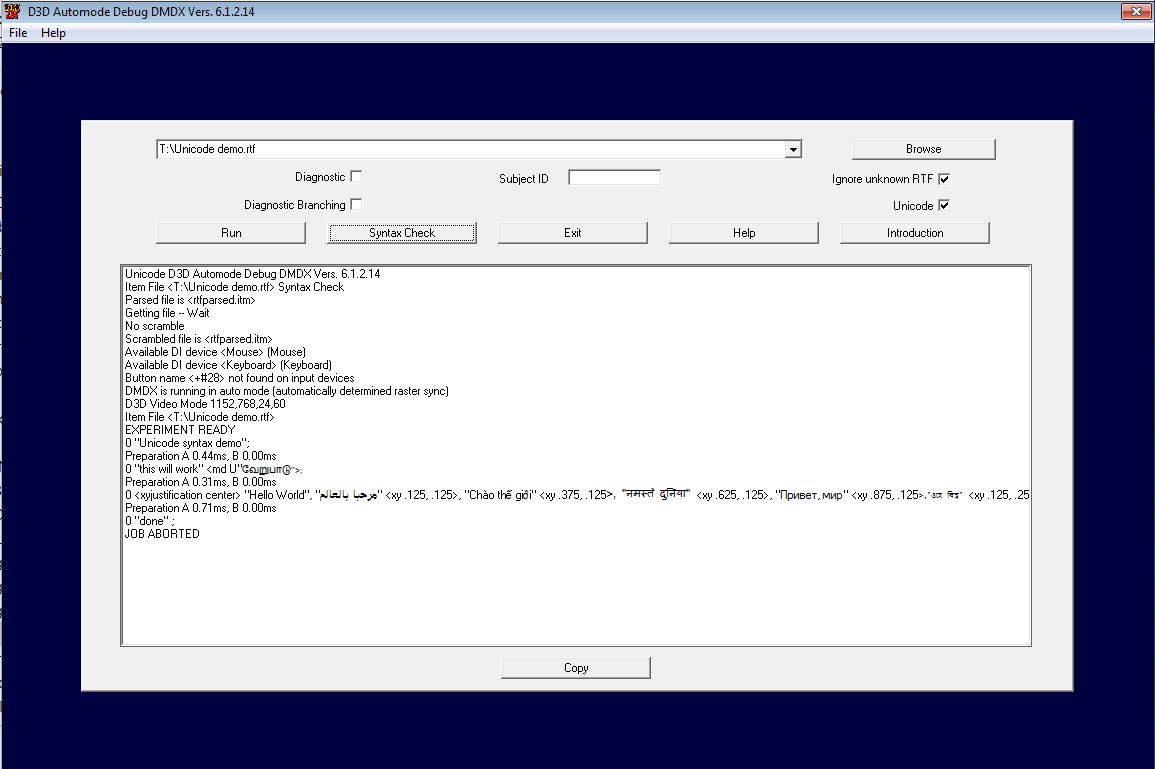
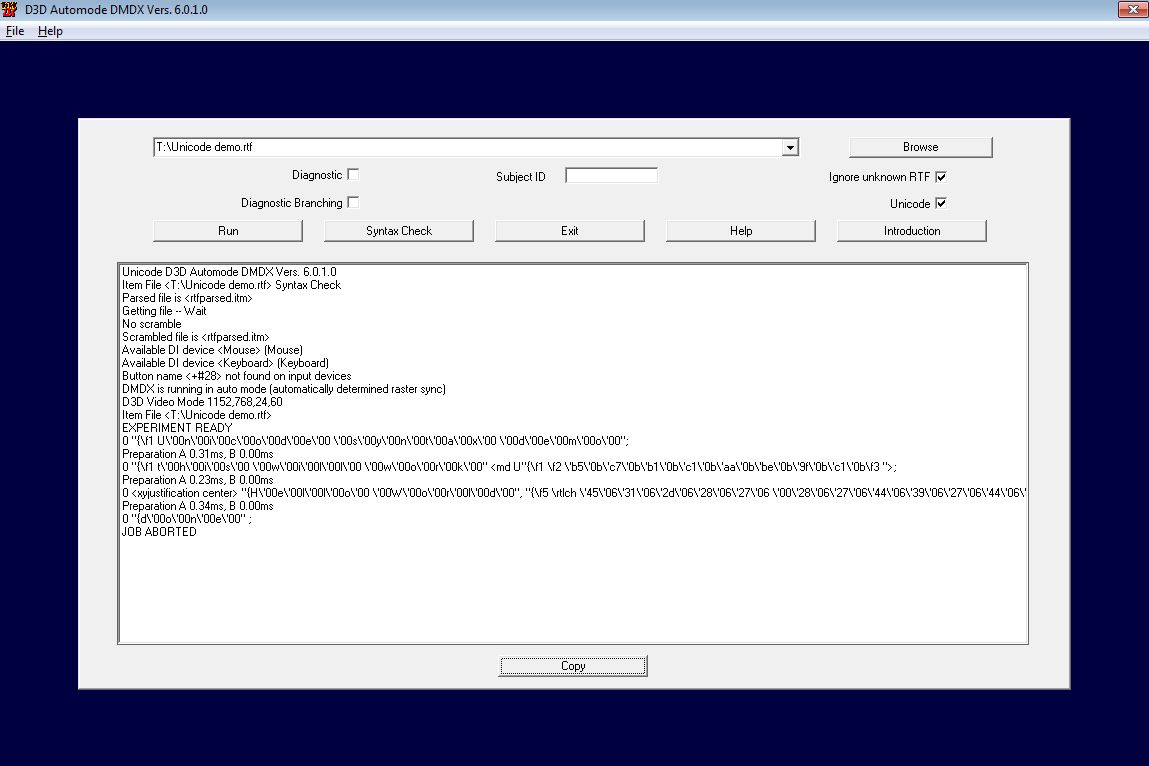
0 "Unicode syntax demo";
0 "this will work" <md U"வேறுபாடு">;
0 <xyjustification center> "Hello World",
"مرحبا بالعالم" <xy .125, .125>, "Chào thế giới" <xy .375, .125>,
"नमस्ते दुनिया" <xy .625, .125>, "Привет, мир" <xy .875, .125>,
"ওহে বিশ্ব" <xy .125, .250>, "ಹಲೋ ವರ್ಲ್ಡ್" <xy .875, .250>,
"你好,世界" <xy .125, .375>, "سلام دنیا" <xy .875, .375>,
"សួស្តីពិភពលោក" <xy .125, .500>, "салам дүйнө" <xy .875, .500>,
"สวัสดีชาวโลก" <xy .125, .625>, "హలో వరల్డ్" <xy .875, .625>,
"هيلو ورلڊ" <xy .125, .750>, "ሰላም ልዑል" <xy .875, .750>,
"Γειά σου Κόσμε" <xy .125, .875>, "こんにちは世界" <xy .375, .875>,
"שלום עולם" <xy .625, .875>, "안녕하세요 월드" <xy .875, .875>;
0 "done" ;
A syntax check in version 6.0.1.0 would have looked like this under Windows 7:
Using my debug build of 6.1.2.14 you get this: